Enter the Gallery to take a look at its construction, and clips of Grimace in action as he tries to find light while avoiding obstacles ![]()
http://www.arpith.com/media/papers/tcpcc.pdf
Abstract: In this project, we investigate the effect of splitting a single TCP connection into several shorter connections taking the same route. The main motivation for these experiments is to study the inherent tendency of TCP to favour (i.e. facilitate achievement of higher throughput on) connections with lower RTT. We observe that TCP indeed performs significantly better on connections with low RTT, and hence are able to speedup a file transfer between two nodes by adding one or more intermediate nodes.
The performance metrics used to compare the TCP performance of the direct connection to that of the the split connections are the Total Transfer time, Average RTT and Throughput. We study this effect for various file sizes, link qualities and number of intermediate nodes. Planet-Lab was used to run a large number of experiments for this analysis.
http://www.arpith.com/media/papers/usb-ultrasound.pdf
Abstract— The project implements two designs on the Xilinx Spartan-II FPGA using an FTDI USB1.1 IC. The first design is a simple loopback that receives data from the host via the USB and retransmits it back to the host PC. The second design transmits selected scan data from an ultrasound backend to the PC host, supporting a maximum of 5 frames per second. To achieve acceptable frame rates on a USB1.1 bus, the amount of data transferred was cut down by a factor of four by selecting the sample closest to each pixel. VHDL was used to describe the hardware design, which was simulated with ModelSim and synthesized using the Xilinx tools. Linear interpolation was used to generate a 512 x 512 image from the scanned data.
]]>Enter the Gallery to take a look at its construction, and clips of Grimace in action as he tries to find light while avoiding obstacles ![]()
Using a map built by exploring a world (as mentioned in the previous article) the code plans a path (not necessarily optimal) from the starting position to the goal position.
The "wavefront" path planning algorithm is simple, but quite effective. It is able to find a path through free space, avoiding obstacles and all locations not explored as yet.
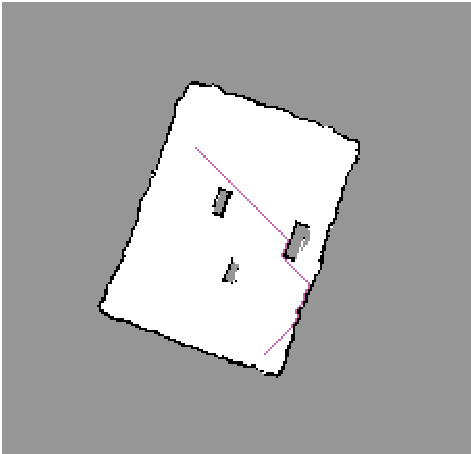
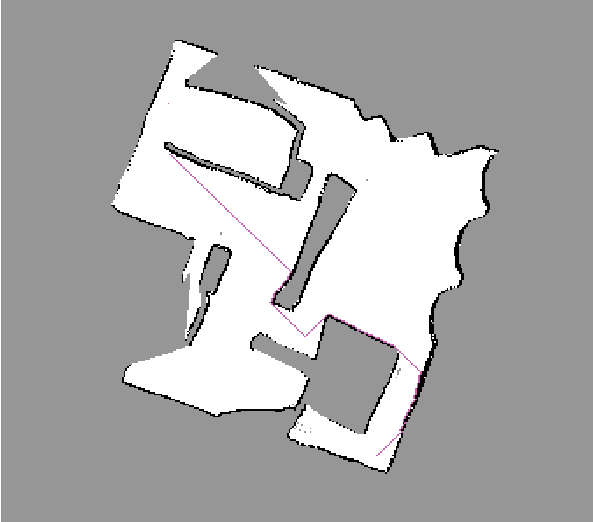
Notice how the path planned "hugs" the wall. This is a consequence of the simplicity of the path planning algorithm and will cause undesired (duh!) collision with obstacles. We can however get over this problem very easily by "growing" the obstacles by the size of the robot.
In the following images, the obstacles are "grown" by a few cells (the areas marked in light pink) before planning is done. This guarantees a safe path that the robot can take.

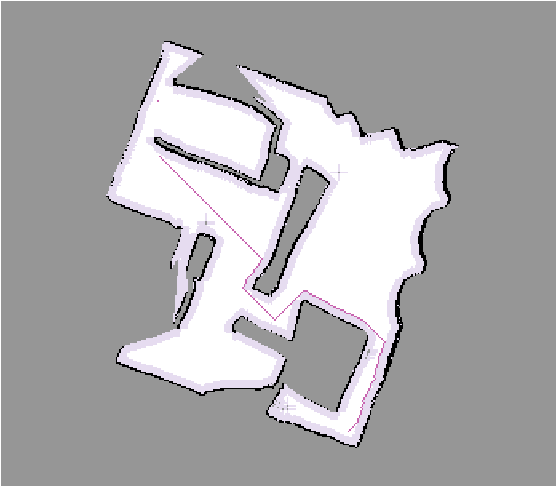
In one of my recent labs, I had to build a map of the robot's world using only its laser sensors to detect obstacles. The laser sensors typically have a span of 90 degrees, with a laser ray emitted at every degree. By measuring the time taken for the ray to hit an obstacle and return, the distance to the obstacle can be measured. Of course, the robot is constantly moving, and the laser sensors aren't perfect, so they don't always return the most accurate readings!
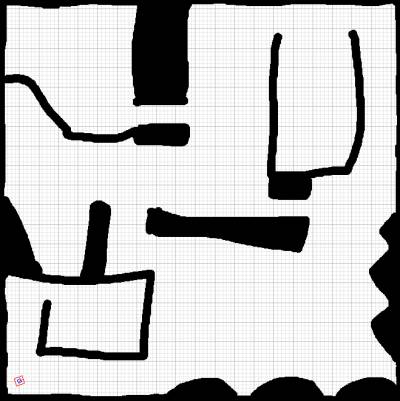
Take a look at the world I used. The robot's starting orientation is arbitrary (in this case it starts off at the bottom left corner at an angle to the horizontal).
The robot is programmed to move to a goal position, avoiding obstacles using the "force potential" method. A resultant vector (direction) is calculated by considering all obstacles in the robot's immediate vicinity as exerting repulsive forces, and the goal position as exerting a strong attractive force.
The software maintains an internal representation of the world using a large 2 dimensional array. Each cell represents a 10cm x 10cm grid position in the world. Cells that are occupied are coloured black, empty cells white, and cells that have not yet been explored are marked grey.
The goal is to map as much of the world as possible in the shortest time. In addition, I didn't want to complicate matters and decided against using any path planning algorithms.
The problem is challenging, and my solution isn't optimal, however it does produces reasonable results. When the robot's laser sensors detect an obstacle, the corresponding cell in the internal map representation is marked as occupied. In addition, all cells in the line segment connecting the robot to the obstacle are marked as unoccupied.
That works well, but we want the robot to explore areas that it hasn't visited yet! The world occupies just 1/9ths of the robot's internal map representation. Can we just pick a random unexplored area in the world and move toward it? Of course there might be a number of obstacles preventing that. We might be able to break down the problem into a number of sub-goals designed to avoid obstacles directly in the path of the robot's path. Or, the unexplored area might be in a boxed enclosure. When do we decide to give up on the goal?
My algorithm instead explores an area in the immediate vicinity of the robot (for example a rectangular area, centered on the robot). It picks a random position in this area that has not been visited, and checks to see if there is a straight line path to it without any obstacles in the robot's way. If so, the robot moves toward that goal exploring areas around the goal.
I omit the implementation details (force potential method, detecting obstacles in a straight line path) for brevity's sake, besides it isn't too hard anyway. This method actually turns out to be pretty effective. It explores a fair amount of the world in reasonable time, is able to navigate through narrow pathways and squeeze itself through tiny openings!
Take a look at the map of the world generated after 5 minutes of running time...

... and 20 minutes...

Anyone have better (and simple) ideas?
]]>Schumacher said: "You know in formula one you should never give up. If you know me, I never do."
"I'm Michael Schumacher. I don't need to test my driving ability, but it's certainly interesting to do what I have to do from where I am now."
]]>Copyright (C) 2003 Arpith Chacko Jacob
Download sw-simd-x86-1.0.0.2.zip
This package includes a parallel version of the Smith Waterman algorithm using Multimedia Extension Instructions on Intel platforms. See [1] for complete details. Two approaches, diagonal [2] and horizontal [3] are used.
The source is written in C and Assembly, and may be compiled using the GNU C compiler and the GNU Assembler. Implementations for MMX (on Intel Pentium with MMX, Intel Pentium II), SSE (Intel Pentium III) and SSE2 (Intel Pentium 4) are available. A processor detect routine that should run on most Intel 486 machines and above selects the best possible implementation during runtime, according to the technology available on the processor.
Byte (maximum possible score 255) and word (maximum possible score 65535) precision implementations are available. The actual maximum score for each precision will vary according to the similarity matrix. Negative scores are eliminated from the SW comparison matrix by biasing the similarity matrix, hence increasing the precision (since one bit is no longer needed for the sign bit). The bias value is the most negative value in the similarity matrix and is added to each element in the matrix. Hence the maximum score for the byte and word precisions are 255 - BIAS and 65535 - BIAS respectively.
The horizontal MMX and SSE approaches perform better than the corresponding diagonal approaches for standard gap penalties, and hence should be prefered on Pentium III machines or lower. The diagonal SSE2 approach performs better than the horizontal SSE2 approach for standard gap penalties, and hence should be used on Pentium 4 machines or higher. The horizontal approach performs far better however, for extremely large gap penalties (of the order of 40 + 2k, see [1]).
Limitations:
To compile:
To execute:
h Horizontal approach
d Diagonal approach
mmx MMX Technology
sse SSE Technology
sse2 SSE2 Technology
auto Automatically detect best technology available
b Byte precision for scores
w Word precision for scores
bw Byte and Word precision for scores
a Protein search
n DNA search
database FASTA database file containing multiple
sequences in FASTA format
query FASTA query file containing a single
sequence in FASTA format
sim_matrix Similarity matrix
gap_init Gap initialization penalty (positive integer)
gap_ext Gap extension penalty (positive integer)
Sample:
References:
[1] Arpith Chacko Jacob, "Whole Genome Comparison using Commodity
Workstations," B.E. thesis, 2003.
[2] Andrzej Wozniak, "Using videooriented instructions to speed up sequence comparison," Computer Applications in the Biosciences, 13(2):145-150, 1997.
[3] Torbjorn Rognes and Erling Seeberg, "Six-fold speed-up of Smith-Waterman sequence database searches using parallel processing on common
microprocessors," Bioinformatics, 16(8):669-706, 2000.
http://www.arpith.com/media/papers/jacob03pdsw.pdf
Abstract— Whole genome comparison consists of comparing or aligning two genome sequences in the hope that analogous functional or physical characteristics may be observed. Sequence comparison is done via a number of slow rigorous algorithms, or faster heuristic approaches. However, due to the large size of genomic sequences, the capacity of current software is limited. In this work, we design a parallel-distributed system for the Smith-Waterman dynamic programming sequence comparison algorithm. We use subword parallelism to speedup sequence to sequence comparison using Streaming SIMD Extensions (SSE) on Intel Pentium processors. We compare two approaches, one requiring explicit data dependency handling and the other built to automatically handle dependencies. We achieve a speedup of 10 - 30 and establish the optimum conditions for each approach. We then implement a scalable and fault-tolerant distributed version of the genome comparison process on a network of workstations based on a static work allocation algorithm. We achieve speeds upwards of 8000 MCUPS on 64 workstations, one of the fastest implementations of the Smith-Waterman algorithm.
]]>The BBC News Online Photographer of the Year competition aims to find the best photographer - decided by internet users - from a selection of photos sent in on various themes. Round one was on "Street Life" and David's entry was one of 14 featured on the BBC's site.
]]>Personal messages may be sent to my address at  . If you would like to email large attachments or forwards, please use the address
. If you would like to email large attachments or forwards, please use the address  .
.
I should be able to reply to your email within a day or two.
Thank you.
]]>